今天在技术群里有位童鞋问了一个问题:
On 64-bit Windows, if a data structure is misaligned, routines that manipulate the structure, such as RtlCopyMemory and memcpy, will not fault. Instead, they will raise an exception. For example:
#pragma pack (1) // also set by /Zp switch struct Buffer { ULONG size; void *ptr; }; void SetPointer(void *p) { struct Buffer s; s.ptr = p; /* will cause alignment fault */ ... }You could use the UNALIGNED macro to fix this:
void SetPointer(void *p) { struct Buffer s; *(UNALIGNED void *)&s.ptr = p; }
我搜了一下,这段话来自Porting Issues Checklist这篇文章。
他的问题是:「我对这句 s.ptr = p 不太明白。为什么会引发对齐错误,什么意思?」
我的回答(当时的原话,貌似有点凌乱,群里讨论嘛,想一句说一句,见谅):
- 因为s这个结构体的首地址是被编译器默认对齐的。由于「#pragma pack (1)」,s.ptr肯定不在对齐的地址上。所以访问s.ptr时会触犯x64 win的对齐规定,于是抛出异常。
- 对于x86架构,对于类似这种没有对齐的地址访问,win内核会自动帮你处理好,用户感觉不到这个问题的存在。但实际上会导致系统性能下降。 到了x64架构,win决定不帮用户擦屁股了。于是就会抛出异常。
- x64是按照8字节对齐,&s是对齐的,那s.ptr是处在 (N*8 + 4)的地址上,于是没有对齐。
这时另一位提了一个问题:「#pragma pack (1) 了,对齐地址是按1的倍数来的,为什么会s.ptr不在对齐的地址上啊?」
我的回答:「pragma pack的对齐只是影响编译器对结构体的padding,这个俗称的对齐,跟硬件手册里的对齐,不是一回事。」
回答完后觉得心理有点不踏实,主要的不确定点是回答3中的「x64是按照8字节对齐」。翻了下手册,果然没这么简单。
(x64架构的)cpu的对齐是根据数据类型的不同而不同的,对于第一个问题,s.ptr是个指针,确实是按照8个字节来对齐的,所以我的回答没有问题。
更具体的对齐在《AMD64 Architecture Programmer’s Manual Volume 2: System Programming》的「8.2.17 #AC—Alignment-Check Exception (Vector 17)」,如下图:
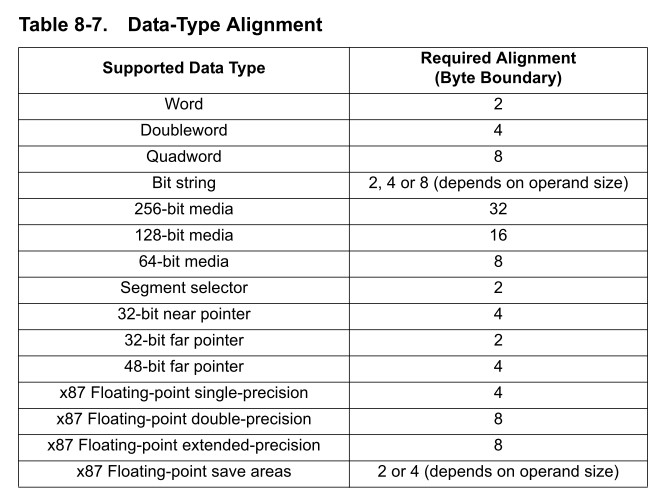
还有个问题,为什么不对齐就会影响性能?
以x64位下的void*数据类型为例,void*是8个字节大小。如果某void* p没有按照8字节对齐,比如下图所示:
addr: N*8 (N+1)*8
| |
offset: 0 1 2 3 4 5 6 7
+-+-+-+-+-+-+-+-+-+
| |X|X|X|X|X|X|X|X|
+-----------------+
^
|
p
如果按照8字节对齐,即ptr处在N*8的位置,那么当需要访问ptr的时候,把ptr的值从mem读到cpu cache,只需要一次读取操作(从N*8到N*8+7,正好8个字节)。
但是如果如上图所示,那么就不得不读两次,第一次也是从N*8到(N+1)*8,第二次读取(N+1)*8到(N+1)*8+7,然后还要把第一次读的后7个字节和第二次读的第一个字节拼起来。此外,在多核环境下,为了保证对ptr的读取操作的原子性,还必须额外消耗一个bus control。另外,unaligned的ptr还有可能分布在两个cache line中,导致更多额外的处理成本(每次对ptr的修改操作会影响两个cache line,造成更严重的False Sharing)。
再多想想,有人可能会问:对于WORD类型,只要求2字节对齐,那如果具体的内存是这样呢:
addr: N*8
|
offset: 0 1 2 3 4 5 6 7
+-+-+-+-+-+-+-+-+
| | |X|X| | | | |
+---------------+
这样虽然是按照2字节对齐,但是并没有在N*8的位置,会不会有性能损耗?
理论上是有的,因为读取到cpu cache后,还有个+2的操作(理论上有,但我不确定到电路那一层,+0和+2的耗时是不是就等价了)。但即便有这个+2的操作,也没太大影响,因为对cpu cache的操作是非常非常快的,而mem->cpu cache这个操作相对来说就非常耗时了。
总结:性能损耗主要是因为多了一次mem->cpu cache操作。
注:在整理这篇文章之前,我不确定多一次读操作是不是导致性能损耗的主要原因,于是请教sinster师傅,对话如下:
Boxcounter 18:43:11
贾佳师傅,请教个问题:
访问unaligned的数据会造成性能下降,比如64位系统,某个void*类型的数据如果是unaligned。那么访问它时会导致2次从内存到cpu cache的读操作,而如果它是aligned,则只需要一次。
是因为这个原因吗?sinister 18:43:55
是,有些系统直接CORE DUMP了。
一些RISC的,POWER,SPARC,EPIC 都这样
后记1:
提问的童鞋说在x64 WinXP系统里,即使不对齐也没有因为异常而中断下来。 我试了下,确实如此,x64 win7系统,挂着windbg内核调试,单步步过unaligned操作,并没有任何提示和中断等异样。恢复到一个没有任何调试设置的快照,也是如此。应用层也是一样。
继续琢磨,在AMD手册里翻到这么几段资料:
- 还是在「8.2.17 #AC—Alignment-Check Exception (Vector 17)」
After a processor reset, #AC exceptions are disabled. Software enables the #AC exception by setting the following register bits:
• CR0.AM=1.
• RFLAGS.AC=1.
When the above register bits are set, an #AC can occur only when CPL=3. #AC never occurs when CPL < 3.
- CR0中AM标志在第18bit,RFLAGS的AC标志也是在18bit
查看了下我的虚拟机:
0: kd> r efl
efl=00000246
0: kd> .formats 0x246
......
Binary: 00000000 00000000 00000000 00000000 00000000 00000000 00000010 01000110
......
0: kd> r cr0
cr0=0000000080050031
0: kd> .formats 0x0000000080050031
......
Binary: 11111111 11111111 11111111 11111111 10000000 00000101 00000000 00110001
......
可见两个18bit都是0,并没有启用#AC异常。 为了避免是内核调试器对虚拟系统的干扰造成的,我用livekd抓了个本机系统DMP来分析:
0: kd> r cr0
cr0=0000000080050033
0: kd> .formats 0000000080050033
......
Binary: 11111111 11111111 11111111 11111111 10000000 00000101 00000000 00110011
......
0: kd> r efl
efl=00000286
0: kd> .formats 00000286
......
Binary: 00000000 00000000 00000000 00000000 00000000 00000000 00000010 10000110
......
结果是一样的,也没有启用#AC异常。
不明白为什么,难道MSDN上那篇文章里的64bit仅指IA64? 目前暂没什么好的思路,先记到这里吧。(如果有朋友知道原因,请不吝赐教。)
后记2:
发现一篇相关的文章:How to debug unaligned accesses on amd64 using Visual Studio?
其中有一条回复是:
“How do real world Windows developers track unaligned accesses in their code?”. Being a primarily Windows developer myself, I think they just never do it, unless the code has to run on Itanium. And if it has to run on Itanium, the exception will tell the places. What is the real overhead of unaligned access on x86? BTW, you can still use assembly on x64, in .asm files, just not inline assembly.
后记3(2013-01-06):
群里的朋友分享了新资料:__unaligned,里面有这么一段话:
The __unaligned modifier is valid for the x64 and Itanium compilers but affects only applications that target an IPF computer. This modifier describes the alignment of the addressed data only; the pointer itself is assumed to be aligned. The Itanium processor generates an alignment fault when it accesses misaligned data, and the time to process the fault weakens performance. Use the __unaligned modifier to cause the processor to read data one byte at a time and avoid the fault. This modifier is not required for x64 applications because the x64 processor handles misaligned data without faulting.
也就是说,确实只有在IA64环境才会凸显出来。